Wren AI Service
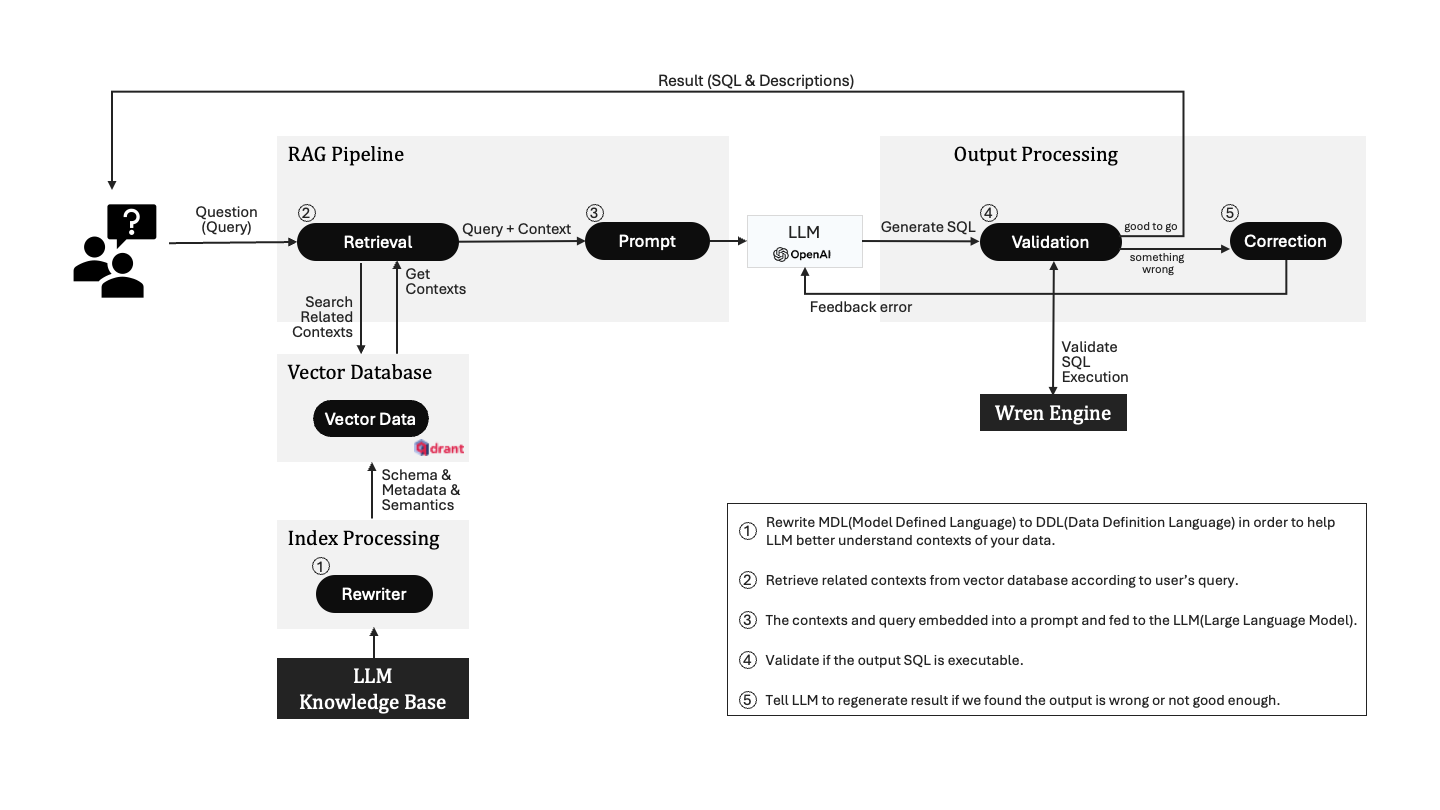
This diagram presents the flow of the AI service provided by WrenAI, which appears to involve the interaction of a large language model (LLM), such as OpenAI's GPT, with a knowledge base to process and answer queries. Here's an overview of the process according to the graph:
Index Processing :
The process begins with rewriting Model Defined Language (MDL) to Data Definition Language (DDL) to aid the LLM in better understanding the context of the data.
Vector Database:
A vector database specializes in efficiently storing and searching vector data. The vector data is where the semantic contexts are stored in a manner that's searchable by the AI.
RAG Pipeline:
- Retrieval: This is where the Wren AI service searches for contexts related to the user's query within a vector database.
- Prompt: Wren AI Service constructs a prompt that includes both the query and the context retrieved from the vector database. This prompt is designed to facilitate the generation of a relevant and accurate response by the LLM.
- LLM: The large language model receives the prompt and generates SQL and descriptions to create a result that corresponds to the user's initial query.
The LLM we are using in this version:
- Embedder: OpenAI text-embedding-3-large with dimension 3072
- Generator: OpenAI gpt-3.5-turbo
Please look forward to future versions that we will offer more LLM options.
Output Processing:
- Validation: The SQL generated by the LLM is validated to ensure it is executable. Wren AI service collaborate with Wren Engine to execute SQL and validate the results.
- Correction: If there is an error detected during validation, or if the SQL is not considered "good enough", the system flags this and the LLM is prompted to regenerate the output.
Overall, Wren AI service combines the natural language processing capabilities of a large language model with the precision of database querying and validation to provide a robust AI-powered query answering service.